 |
| Server Logs (Photo credit: novas0x2a) |
Data, Data From Everywhere On The Server And Not A Byte To Benefit From….
All those who are in the web solutions business since early 2000 know that prior to Google Analytics , the most trusted analytics data was the log files on the server. In fact those log files are still in fact the most accurate and raw data available for the actual activity taking place on the server.
Server logs are automatically created recording the activity on the server and they are saved as a log file on the server itself. Usually the log file is saved as a standardized text file but it may vary at times depending on the server. Log files can be used as a handy tool for web masters, SEOs and administrators. They record each activity on the server and offer details about – what happened, when and from where on the server related to that domain. This information can record faults and help their diagnosis. It can identify security breaches and other computer misuse. It can be used for auditing and accounting purposes too.
A plain text format minimizes dependency and assists logging at all phases . There are many ways to structure this data for analysis, for example storing it in a relational database would force the data into a query-able format. However, it would also make it more difficult to retrieve if the computer crashed, and logging would not be available unless the database was available.The W3C maintains a standard format for web server log files, but other proprietary formats exist. Different servers have different log formats. Nevertheless, the information available is very much the same. For example the fields available are as follows: ( It may not be necessarily recorded in the same order on all servers)
· IP address
· Remote log name
· Authenticated user name : Only available when accessing content which is password protected by web server authenticate system.
· Timestamp
· Access request : “GET / HTTP/1.1”
· The request made. In this case it was a “GET” request (i.e. “show me the page”) for the file “/” (homepage) using the “HTTP/1.1” protocol.
· Detail information about HTTP protocol is available inhttp://en.wikipedia.org/wiki/HTTP.
· Result status code : “200”
· The resulting status code. “200” is success. This tells you whether the request was successful or not.
· For a list of possible codes, visit http://en.wikipedia.org/wiki/List_of_HTTP_status_codes.
· Bytes transferred : “10801”
· The number of bytes transferred. This tells you how many bytes were transferred to the user, i.e. the bandwidth used. In this case the home page file is 10801 bytes, or about 10K.
· Referrer URL
· User Agent
Following is the example of the data which was exported to Excel from the log file:
Example 1:
180.76.6.233 – – [29/Apr/2012:05:04:56 +0100] “GET /blog/microsoft-windows-vista-ultimate-with-sp2-64bit-oem/ HTTP/1.1” 404 39621 “-” “Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)”
Example 2:
On some servers the fields will be mentioned in the log file before recording the data as follows and then the corresponding data for that date will be displayed:
#Fields Per Record: date time cs-method cs-uri-stem cs-username c-ip cs-version cs(User-Agent) cs(Referer) sc-status sc-bytes
Data Per Record: 2012-05-01 01:19:17 GET /seo-web-design.htm – 207.46.204.233 HTTP/1.1 Mozilla/5.0+(compatible;+bingbot/2.0;++http://www.bing.com/bingbot.htm) – 200 12288
Well, it is not as geeky as it looks , in fact it is very smiple. The data from the log files can be retrieved easily by importing the text data in Excel or by using standard software available for extracting data from log file like the “WebLog Expert” the sample report generated can be viewed on http://www.weblogexpert.com/sample/index.htm
The analysis of the log files can offer some great insights about the traffic on the server and many times the spam on the server and a hacking attack can be detected early and the harm on the sites can be reduced to a great extent as the corrective action can be taken immediately. This can be a real boon to every SEO as this data will be reflected in WMT much later.
The data can be filtered out as per the fields which need to be tracked. For example you can see in the image below how the WebLog Expert software shows the data graphically and numerically for the filtering that we did to trace the Google, Bing and Baidu bot activity on a particular domain .
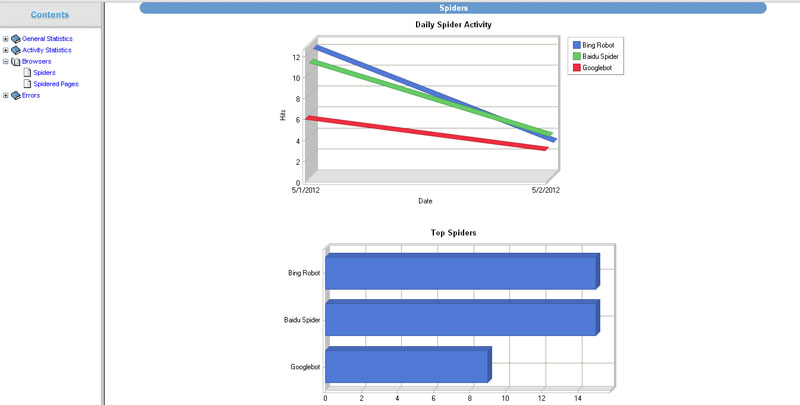
Keeping a track of this data can give us information related to the crawling of the bots , downloads, spam attacks, etc. Of course , after all it is all raw data and just data in itself is meaningless but how you correlate and connect the dots to come to correct conclusions to take the right decisions is what makes the difference.
For me it is a Déjà vu feeling as when we did not have Google Analytics the server log files and Webalizer were the only resource. Sometimes, going retro is the coolest thing to do because, some trends which seem to be new are actually very old.